

闻乐 发自 凹非寺
字节Seed皆出手用化学念念想搞大模子了——
深度推理是共价键、自我反念念是氢键、自我探索是范德华力?!
传统的大模子长念念维链推理基本把AI的念念考经过等同于线性结构。
但很厚情况下,后续的一个关键论断,可能需要回过甚去考据早早建议的假定。
CoT把这种非线性的依赖关系忽略了。
字节Seed在论文《The Molecular Structure of Thought》中初次给大模子的长链念念维界说了分子式结构。

在这种分子拓扑中,三种键是奈何互额外合的?
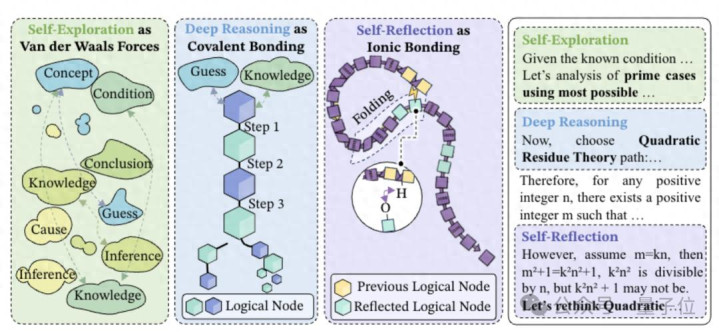
好的推理像分子结构
团队把DeepSeek-R1、gpt-OSS等强推理模子的长链念念维拆成一步一步的,然后给每一步之间的“卓越”打上标签。
打完标签发现,系数灵验的长链念念维里,其实就三种基础手脚往复组合。
第一种叫深度推理,像共价键一样结子。
泛泛来说即是近似“因为A是以B,因为B是以C”的硬逻辑推动。
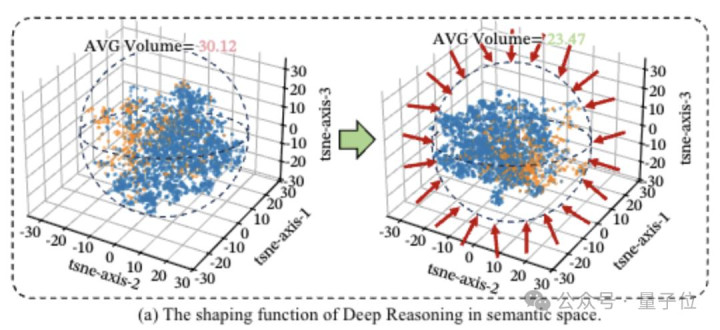
团队在语义空间里作念了一个很形象的量化分析,把模子的每一步念念考皆当成一个点,看这些点临了会散成多大一个圈。
圈子越小,证实模子越没跑题,念念考越聚焦。
限定发现,加上深度推理之后,这个散点圈平直缩水22%。
深度推理如实起到了收束杂念、锁定中枢逻辑的关键作用。
第二种叫自我反念念,像氢键一样有弹性但褂讪。
近似于“等等,我刚才那步是不是想错了”“让我再行搜检一下前边的假定”,能把背面的念念考拐总结跟前边的节点呼应上,造成一种折叠感。
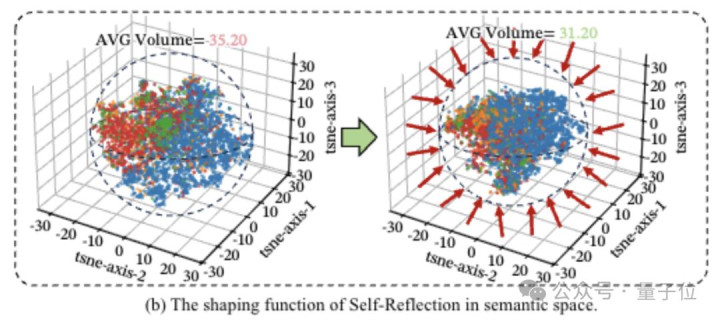
团队测了模子自我反念念时的念念维轨迹,把每一步念念考皆看谚语义空间里的一个点,然后筹办反念念时会跳回多远、落在何处。
发现81.72%的反念念行动,皆会精确落回之前仍是造成的靠谱念念路区域里。
还对比了反念念前后的念念维边界,反念念前,语义空间体积是35.2,反念念后,平直压缩到31.2。
再看聚类限定就更明晰了,反念念之后,吞并类正确念念路的点会牢牢抱团,而那些脱落、跑偏的分支会被自动推开。
也即是说,自我反念念氢键能把靠谱逻辑揉得更紧实、把跑偏主见筛出去、稳住系数这个词推理大局,让长链念念考不再松散零碎。
第三种叫自我探索,像范德华力一样弱,但掩盖面广。
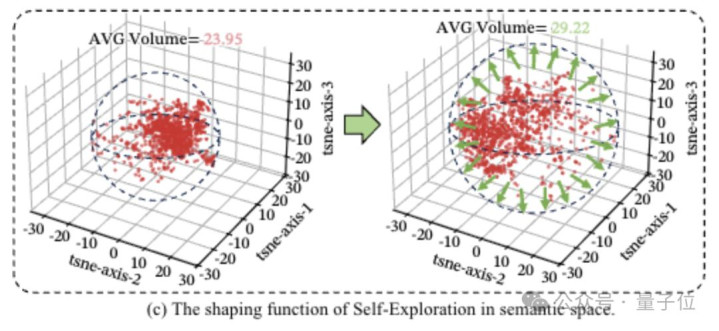
这个就近似于“要不我们试试这个角度”“有莫得另一种可能性”,在语义空间里找新的解题旅途。
量化分析败露,加上探索行动之后,模子在语义空间里的念念维掩盖边界能从23.95扩大到29.22。
自然念念路一通达褂讪性就会下落,容易跑偏想歪,但能让模子跳出死巷子,不卡在局部最优解里,果真找到全新的解题道路。
研究发现,系数强推理模子的三种念念维行动比例和调度规章皆高度一致,关系性卓越0.9,证实灵验长链推理存在通用的褂讪拓扑结构。
你可能合计“共价键”“氢键”仅仅个譬如,但论文发现,这个譬如背后藏着严格的数学对应。
在Transformer里,珍见识权重的筹办表情长这样:
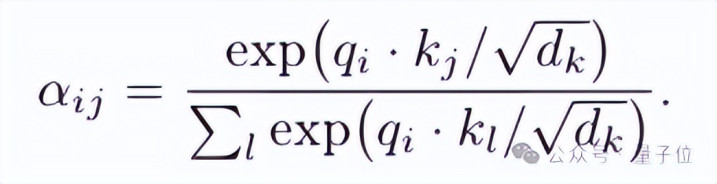
眼熟吗?这和统计力学里的玻尔兹曼分手一模一样:
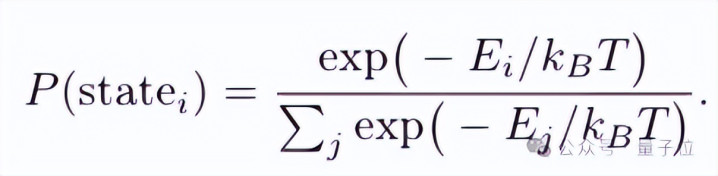
要是把负珍见识分数看作能量,那么珍见识权重即是模子在语义空间里按“能量”上下遴荐旅途的概率即是能量越低,被选中的概率越高。
论文进一步分析了三种行动对应的“珍见识能量”。
深度推理络续发生在相邻行动之间,开云app能量最低;
自我反念念会跳回较远的行动,能量中等;
{jz:field.toptypename/}自我探索跳得更远,能量最高.
这就施展了为什么强推理模子的三种键比举例斯褂讪。
因为模子的珍见识机制自己就在追求最粗劣量的推理旅途,而深度推理、反念念、探索碰劲对应了不同距离下的能量层级。
语义同分异构体和智能熵减
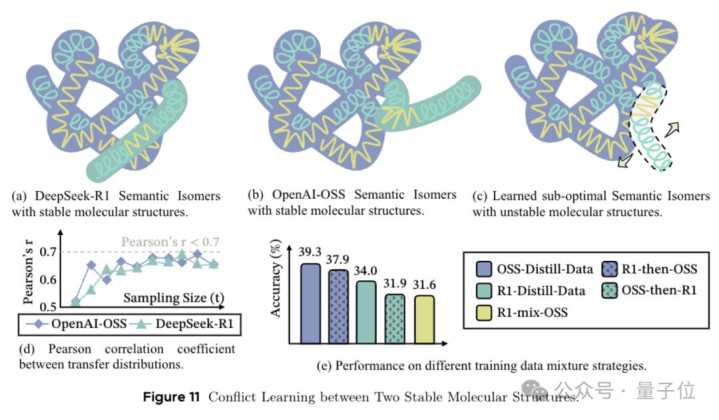
接着团队还抛出了语义同分异构体的看法。
这词儿是借的化学,一样的分子式,原子一语气表情不同,就能搞出性质齐全不同的物资。
放到推理里即是,一样的题目,一样的看法点,用不同的”化学键“组合去解,出来的推理链条不错齐全不一样,但皆能解对。
但不是系数异构体皆允洽拿来教模子。
这里就要引入一个关键看法熵减。
在热力学里,一身系统老是自愿走向零碎(熵增),而一个灵验的长链推理经过,履行上即是在语义空间里不停缩小不细目性——
从一堆可能的处所中,清闲管制到独一正确的谜底。这个经过即是“熵减”。
而“珍见识能量”机制,恰是模子达成熵减的器具。
模子的珍见识自然偏好能量更低的旅途。
当深度推理(粗劣量)被反复选中,反念念(中等能量)把前后逻辑折叠起来,探索(高能量)偶尔探路但不喧宾夺主,系数这个词系统的“推理熵”就会快速下落,逻辑火速管制。
这如论文里说的,只须那些能推动熵快速缩小的“化学键”组合,才是模子果真能学会、能抓续进化的褂讪态。
这在实验中有个很典型的气候,从R1和OSS两个不同强推理模子中蒸馏出的推理轨迹,语义层面的内容相似度高达95%,但混在沿途磨练,模子反而崩溃了。
这证实,长链推理的关键是念念路结构必须褂讪、长入,模子才气学得会。
MoLE-Syn:从零合成褂讪推理结构
发现问题就要科罚问题。
基于这一整套发现,团队搞了个叫MoLE-Syn的行动,来从零合成褂讪的推理结构。
具体操作就两步。
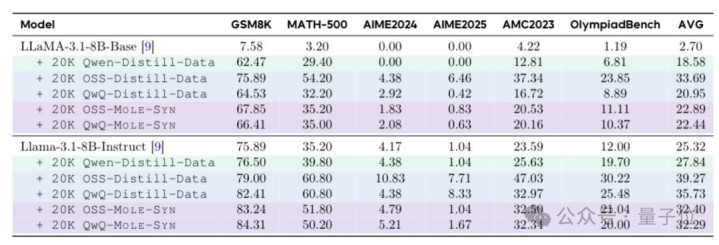
第一步,从强推理模子(比如R1、QwQ、gpt-OSS)的推理链里,抽出一张行动升沉概率图。
这张图里每个节点是一种推理行动(化学键),每条边是从一个行动跳到另一个行动的概率。

第二步,拿着这张图,让泛泛的提醒模子照着图上画的概率去生成推理链。
用这个行动从零合成的磨练数据,喂给Llama简略Qwen,成果迫临平直蒸馏R1的水平。
况兼这样作念有一个大克己即是资本低。只须拿到那张行动升沉图,泛泛模子就能我方出产及格的长链推理数据。
团队把用MoLE-Syn出手化过的模子拿去作念强化学习,发现跑起来还绝顶稳。
比拟平直用蒸馏数据出手化的模子,MoLE-Syn版的在RL经过中收益抓续增长,震憾也小得多。
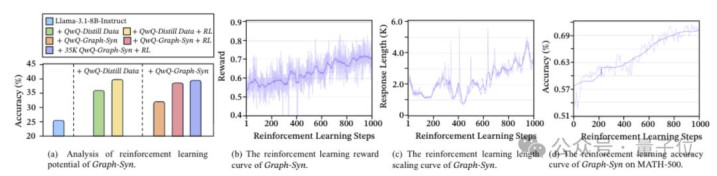
这证实一出手植入的念念维结构够稳,背面的强化学习就不会出现逻辑偏移。
这项研究的正经东谈主为字节Seed算法民众黄文灏,曾在微软亚洲研究院担任研究员。
第一作家是哈尔滨工业大学博士、字节Seed实习研究员陈麒光。
互助单元还包括北京大学、2077AI Foundation、南京大学、M-A-P、中南大学。
不得不说,这波操作有点畴昔薛定谔拿物理学公式推生物学那味儿了。
给大模子推理这个卷得飞起的范畴,开了个挺融会的新脑洞。
论文地址:https://arxiv.org/abs/2601.06002
— 完 —
量子位 QbitAI · 头条号签约
和顺我们,第一时辰获知前沿科技动态


 备案号:
备案号: 